BUAA 2023 编译器设计
本编译器使用 C++17 书写,中间代码为自行设计的四元式,目标代码生成 MIPS。
目录
参考编译器介绍
抽象语法树 AST 设计参照了 https://github.com/dhy2000/Compiler2021 。
由于我只参考了该编译器的 AST,这里着重介绍它的 AST 设计。
抽象语法树结构
语法树采用多种不同的节点类进行表示。 为了方便管理编译作业要求的语法分析输出,定义接口 Component 用于输出语法成分。
对于文法的每种非终结符,建立一种语法树节点类,并用属性来存储其组成成分(词语(终结符, 叶节点)和子节点(非终结符, 非叶节点) 对于组成成分存在 “或|” 关系的非终结符,对其每个具体方向建立类,并让这些类实现同一个接口。
SysY 文法按照不同的逻辑层次进行分类,分别针对每一类依次分析和编码。 根据语法成分出现的层次,分为:表达式、语句、变量定义、函数定义四大类。
文件组织
- 测试
- 前端
- 词法分析
- 语法分析
- 语义分析
- 中间代码
- 后端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
├───autotest
├───backend
│ ├───exception
│ ├───hardware
│ ├───instruction
│ └───optimize
├───compiler
├───exception
├───frontend
│ ├───error
│ ├───input
│ ├───lexical
│ │ └───token
│ ├───syntax
│ │ ├───decl
│ │ ├───expr
│ │ │ ├───multi
│ │ │ └───unary
│ │ ├───func
│ │ └───stmt
│ │ ├───complex
│ │ └───simple
│ └───visitor
├───middle
│ ├───code
│ ├───operand
│ ├───optimize
│ └───symbol
└───utility
总体介绍
总体结构
编译器前端包括词法分析器、语法分析器、符号表、抽象语法树。中端包括中间代码生成。后端包括 MIPS 指令翻译、内存管理、寄存器分配。
词法分析、语法分析和语义分析是同一遍完成的。 语法分析采用递归下降法,同时进行语义分析,并维护符号表。
符号表填表在语法分析、语义分析阶段完成,符号表信息在中间代码生成中被使用。 在 MIPS 指令生成中,不再使用符号表,只使用中间代码包含的信息(符号表信息被储存在中间代码中)。
词法分析、语法分析、语义分析都涉及错误处理,会报告出错行以及出错类型。 除此之外,我还自定义了一些其它错误,方便测试。
语法分析会生成 AST 抽象语法树,对 AST 进行自顶向下进行中间代码生成,产生中间代码的容器 Module。
再对 Module 进行处理,生成 MIPS 汇编指令。
1
2
3
4
5
CompUnit compUnit = CompUnit::parse(); // 语法分析获取语法树
if (!Error::hasError) {
IR::Module module = compUnit->genIR(); // 中间代码生成
MIPS::outputAll(*module); // MIPS 代码输出
}
接口设计
词法分析器提供接口返回下一个词,包含词法类型和具体字符串,被语法分析器调用。
语法分析的具体解析 parse 方法分布在各个抽象语法树节点类中,用于建立 AST。
AST 根节点 CompUnit 包含生成中间代码容器 Module 的方法。
编译器后端解析 Module 来生成 MIPS 汇编程序。
文件组织
编译器源代码文件组织如下: 主要可分为前端(词法分析、语法分析、符号表)、语法树、中间代码、后端 MIPS、错误处理。
其它文件包括有: tools 内的辅助函数,main.cpp 入口,config.h 方便设置版本,Cmake 工程文件,结合 mars.jar 的测试脚本。
1
2
3
4
5
6
7
8
9
10
11
12
13
├───frontend
│ ├───lexer
│ ├───parser
│ └───symTab
├───AST
│ ├───decl
│ ├───expr
│ ├───func
│ └───stmt
├───middle
├───backend
├───errorHandler
└───tools
词法分析器 Lexer
单例模式
原设计仿照 java 实现单例模式。后修改使用 namespace 实现单例效果,更简洁方便。
Lexer Parser 均使用 namespace 实现单例效果,仅向外暴露必要接口 (CppCoreGuidelines 不建议使用单例设计模式,冗余复杂不如namespace一步到位)
预读处理
Lexer 无需为 Parser的 预读处理额外扫描。
Lexer 应当领先 Parser 若干个单词(具体领先数量依据设计而定,单词信息均存储于 Lexer 内部)。
Lexer 共存储 3 个单词(便于 Parser 预读分析,具体深度在 Parser 设计中确定),分别记录每个单词的位置数据(错误处理)。
在读取新单词时,依次更新各个单词信息。
由此优化, Lexer 仅会扫描全文一遍,预读不会影响性能。
词法类型
之前的 Lexer 为了方便输出,直接将词法类型(终结符) LexType 定义为 string。
开发 Parser 考虑建造语法树时,如果使用 string 作为节点标识符,效率太低。
后现将 LexType(终结符) 和 AST(非终结符) 重构为枚举类。
区分标识符和保留字
为了简化代码实现,我借鉴了讨论区同学的 LinkedHashMap。
只需将保留字加入上述 map 中,在区分时依次判断即可,无需实现状态机区分保留字。
CPP 标准库没有 JAVA 的 LinkedHashMap,我使用模板类实现(仅功能实现,未优化效率)。
语法分析器 Parser
语法分析部分的编码前后设计详见章节抽象语法树 AST
语法分析器的实现:各个 AST 节点有各自的语法分析方法,在相应节点类内部作为类方法存在,方法返回语法树节点指针。
1
2
3
4
5
struct CompUnit {
// ...
static std::unique_ptr<CompUnit> parse();
// ...
}
Parser 作为一个命名空间,只包含了语法分析阶段各个节点解析都需要的公用方法:解析单个终结符、输出语法信息。
抽象语法树 AST
原设计:AST 的节点均为一个类,该类成员属性包含 NodeType 用以区分不同节点。
使用映射表<Node* , 具体属性>表示结点的属性信息
(如果在节点内部直接存储信息,每个节点都要包含所有可能的信息,浪费内存)。
上述设计是可行的,但是每次访问属性都要访问指针,破坏了缓存连续性,代码运行效率低,不优雅。
修改后的设计: 在阅读了往届同学和 Clang 源代码后,我决定重构 AST,为每个非终结符设置一个类。
| 对于规则中的“ | ”,我将右侧的每个选项建立新的类,并使右侧的每个选项对应的语法树类继承左侧非终结符对应的类。 |
1
2
3
PrimaryExp → '(' Exp ')' | LVal | Number
struct LVal : public PrimaryExp {..}
节点类包含本身的信息,以及子语法树节点的指针。
多个节点类间使用继承降低复杂度、复用代码,类继承关系图(Visual Studio生成类图)如下所示。
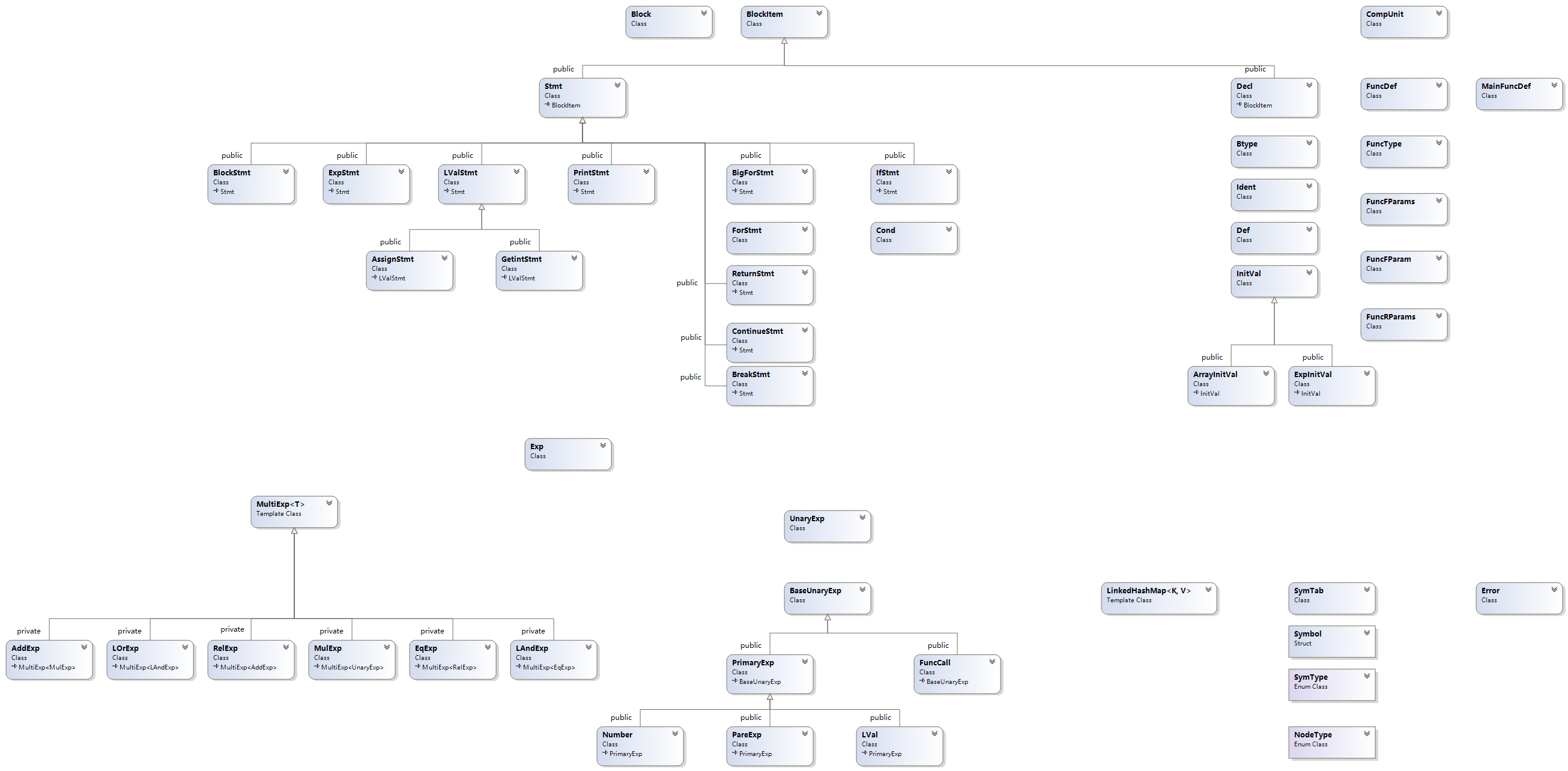
区分 Exp 和 LVal
在 Stmt 解析中,区分 Exp 和 LVal 相对复杂,我通过在分号前寻找=赋值符号进行区分。
const
我的节点中,将 cons 作为 Exp InitVal 的属性,解析时需要向下传递 cons。
1
2
Exp → AddExp
ConstExp → AddExp
文法规定中,没有区分 Exp ConstExp(AST 中,ConstExp 下的节点不为 const),额外添加语义约束。
在后续语义分析时需要注意。
符号表 SymTable
原设计: 栈式符号表,记录当前符号表指针和顶层 global 符号表指针。
修改后的设计: 由于我的实现中,第一遍完成词法分析、语法分析、语义分析,第二遍完成中间代码生成,第三遍完成 MIPS 生成。
中间代码生成和符号表的生长过程(语义分析)不在同一遍内完成, 因此需要在第一遍的语义分析结束后,保留所有符号表,以便第二遍的中间代码生成中访问符号表。 重构后,符号表使用树形结构。
每一个 SymTab 包含了上一级符号表指针、下一级的多个符号表指针、自身包含的符号哈希表(标识符名->符号表表项)、符号表深度。
在全局数据区,记录了当前符号表指针以及全局(最外层)符号表。
1
2
3
4
5
6
7
class SymTab {
SymTab *prev; // prev SymTable
std::vector<std::unique_ptr<SymTab>> next; // next SymTable
std::unordered_map<std::string, Symbol> symbols;
int depth;
// ...
}
每一个符号表表项包含了所有可能的信息,有一定的内存浪费,但是书写代码方便,运行效率较高。
符号表表项是 Symbol,有以下属性:
- 符号类型:值、函数、函数形参
- 数据类型:Void, Int, IntPtr(函数形参为数组地址)
- cons 常量标记
- dims 变量/函数形参的维度
- initVal 常量的初始值
- params 函数的形参表
常值计算
语义分析的符号表填表中,需要解析数组维度,进行编译时常量计算。
符号表作用域
for 语句的 (…) 与 {…} 是同一个作用域,专题报告有错。
符号表深度修改位置: FuncDef MainFuncDef BigForStmt IfStmt BlockStmt (不是在 block 内!)
错误处理 Error Handling
原设计和编码后的设计是一致的。 在后续开发中,我额外自定义了一些错误,会生成到 error.txt 中,用于自己 debug。主要为类型判断。
在词法分析阶段 Lexer 记录错误位置(作业仅要求行号),在词法分析、语法分析、语义分析中完成错误判断、处理。
错误可分为语法错误和语义错误,在 词法分析、语法分析、语义分析中完成。 在我的设计中,中间代码生成和 MIPS生成中不涉及错误处理。
中间代码 IR
数据结构
遍历 AST 语法树,输出中间代码容器 Module(后续继续生成到MIPS)
我的中间表示结构参照了 LLVM IR 的设计: Module 是一个编译单元,我们的项目只有单文件编译,只有一个 Module
1
2
3
Module{Global全局变量表}{Function函数表}
Function{BasicBlock基本块}
BasicBlock{Inst中间四元式}
将全局变量和 const 变量初值存储在符号表中, 常量计算方法访问符号表可以获取 const 变量的值。
中间代码生成中,可以使用符号表的常量信息优化,在编译时就直接带入 const 变量的值,无需在运行时加载。
四元式由4部分组成:Op 操作符、3个 Element 元素。
Element 有4个子类:变量 Var,临时变量 Temp,标签 Label,常量 ConstVal,字符串常量 Str。
类型系统
前端 Parser 需要将类型录入 SymTab,还需要添加函数参数和函数返回值,再将类型录入IR::Module,在 MIPS 生成时不再使用符号表。
本编译器的类型系统不完善,但是足以通过测评。支持多种类型(不止int)需要花费大量精力重构代码。
中间代码生成
如果单独建类 Visitor,在遍历语法树时, 为了区分不同的语法成分,需要多次进行动态类型转换 dynamic_cast(cpp)/instanceof(java) 判断多态性,这么做极其低效,并且代码不优雅。
1
2
3
4
5
6
7
if (stmt instanceof AssignStmt) {
analyseAssignStmt((AssignStmt) simple);
} else if (stmt instanceof BreakStmt) {
analyseBreakStmt((BreakStmt) simple);
} else if (stmt instanceof ContinueStmt) {
...
}
下面修改设计:使用多态性,为 AST 基类提供虚函数,让 AST 派生类重载基类的中间代码生成方法。这样显著提高效率,更加优雅。 这么做,就需要将代码生成方法放入到 AST 节点类中,无需单独建立中间代码生成的类。
不同的 AST 节点类的中间代码生成方法的返回值不同,如 CompUnit 返回 Module,
作用域和栈
为了对应变量在栈上的作用域,我会生成特殊 IR (InStack OutStack) ,将当前的栈偏移量入栈,在结束时出栈恢复相应的偏移量。
1
2
3
4
5
6
7
int a0_0; // curOffset = 4
{ // InStack 保存当前栈偏移量 4
int a1_0; // curOffset = 8
int a1_1; // curOffset = 12
} // OutStack 恢复栈偏移量 4
int a0_1; // curOffset = 8
int a0_2; // curOffset = 12
寄存器冲突
由于寄存器冲突,函数传参使用寄存器 $a0-$a3 会十分复杂,我直接将函数参数保存在栈上传递。
如果将函数返回值保存在 $v0,可能会导致函数返回值覆盖。 我的解决办法是,在获取函数返回值后,立即使用一个临时寄存器保存当前的 $v0。
目标代码 MIPS
函数调用时,生成指令用于维护栈指针寄存器 $sp 偏移量。
我在目标代码生成部分没有使用符号表,将变量的地址都另外自行保存了。 目标代码生成内部存有 变量名->(栈/全局数据区)地址 的映射表。
栈内存分配
遇到特殊 IR (InStack OutStack) 时,会改变当前的 $sp 的偏移量。
临时变量的寄存器/内存分配策略
IR::Temp -> real Register
$t0 开始设置临时寄存器,只需修改 MAX_TEMP_REGS 即可调整临时寄存器数量。为保证程序正确性, MAX_TEMP_REGS 最小值为4。
若没有可用临时寄存器,则将临时变量存储到内存中。 所有临时变量只生成一次,只使用一次,getReg()使用后马上释放寄存器。
函数调用
1
2
3
4
5
6
7
8
9
MIPS stack memory map
In funcCall, StackMemory::curOffset = 0
0 -> 4GB
$sp
↓
s7 ... s1 s0 | t7 ... t1 t0 ra sp | p0(parameter) p1 ... pN-1 |
-18 ... -12 -11 | -10 ... -4 -3 -2 -1 | 0 1 ... N-1 |
-------------
MAX_TEMP_REGS = 8
函数调用保存现场时,会保存当前使用的临时寄存器,但分配总额 MAX_TEMP_REGS 的栈内存,这样被调用的子函数在定位栈内存时就无需考虑父函数使用了多少临时寄存器了。
另一种方法是,在 jal 之前将已使用的 tempRegs 数量保存到某实际寄存器 realReg $?,使用 realReg $? 代替 $sp 来定位内存(速度较慢,但栈内存占用较少)。
竞速仅考虑速度,这里不考虑爆栈。这里的选择是空间换时间。
代码优化
由于本学期选修了较多课程,后期优化时间有限。
中间代码优化已经被融合在了代码生成部分。 主要进行了后端优化。
临时寄存器分配
我使用了 $t0-$t8 作为临时寄存器池,使用先进先出的规则,为中间代码的临时变量分配临时寄存器。
如果临时寄存器不足,则将该临时变量存储到内存当中。
为保证正确性,临时寄存器池应当至少包含 4 个寄存器。
全局寄存器分配
中间代码生成 Alloca 指令,为变量分配栈内存。
在后端 MIPS 代码生成中,我依照先进先出的规则(时间限制,没有使用图着色算法),为变量分配8个寄存器 $s0-$s8,其余变量放在内存中。
在超出变量的作用域后,会释放该变量对应的寄存器。
在竞速测评中,我尝试扩大8个寄存器为10个,但是结果一致,我推测全局寄存器没有被完全分配,测试点内的变量冲突较少。 因此使用其它寄存器分配算法结果也是一样的?
常量计算
在数组下标计算部分,我会尝试在编译期计算出偏移量,避免在生成的目标代码中包含偏移量计算指令。
后端指令合并
MIPS 部分指令支持立即数直接参与计算,无需提前加载到寄存器中。
li $t1 1
addu $t2 $t0 $t1
------------------
addiu $t2 $t0 1
move 指令也可以与相邻的指令合并。
原地跳转指令消除
跳转指令如果跳转到的是下一个基本块,就可以消除该条无效跳转指令。